
 In Part 1 of this series, I introduced the notion that project managers can learn a lot from airline industry professionals and their great safety systems and also apply those principles to projects in trouble or that have already crashed and burned.
In Part 1 of this series, I introduced the notion that project managers can learn a lot from airline industry professionals and their great safety systems and also apply those principles to projects in trouble or that have already crashed and burned.
In this segment of “Mayday: Project Crash Investigation,” I continue with this airline industry metaphor. First, I offer ideas that will prevent you from making the same mistakes in your future projects, and then we go over how to get better at diagnosing projects currently in trouble.
First Step: Secure Your Data
When a project fails, it’s important to investigate the crash with the same rigor used by aviation experts when dealing with catastrophes within their industry. As I watched all 16 seasons of the TV series Mayday: Air Crash Investigation, the first thing I noticed was that crash investigators immediately secured the crash site, preserving all relevant data, wherever the clues were strewn. The second thing I noticed is that crash investigators always looked at the scene with an open mind and tried not to form any conclusions until a full investigation was conducted.
For example, there are numerous examples of jumbo jets crashing or otherwise failing to land safely during severe inclement weather, but after a thorough investigation for many, if was found that mechanical failures or pilot error was to blame, and not the storm that engulfed the craft. But these investigations would never have uncovered the cause if the crash site hadn’t been secured first to enable all details of the crash to be examined.
In that light, when your project fails, the first thing to do is to secure all data relating to the project: from its inception documents (concept notes, proposal, RFPs, EOIs, etc.) to the project’s implementation documents (budgets, workplans, schedules, risk management plans, etc.). In addition to this paper trail, what was said during the project — emails, chat logs, meeting minutes — should also be secured for the investigation.
These vital bits of data can be likened to the cockpit flight recorders — both the flight data recorder (FDR) and the cockpit voice recorder (CVR). For most of us, Microsoft Project makes a great FDR for our projects, recording all that happens during the life of the project — with snapshots in time (baselines) that show us how our projects perform (or not) over time. If we’re fortunate enough to be using Project Server or Project Online, we may also have the “soft” data found in comments and emails, essentially having a CVR as well.
Using Microsoft Project as Your Flight Recorder
Project is a well-known tool for creating and monitoring schedules, but another useful aspect of this tool is its built-in database capabilities. Using Task Information/Notes is a great way to have any ancillary data about your project attached directly to that project. In addition to plain text notes written at the task level, you can also attach associated Word, Excel, PDFs, or any other docs relevant to your project. I usually do that in the first task of the plan.
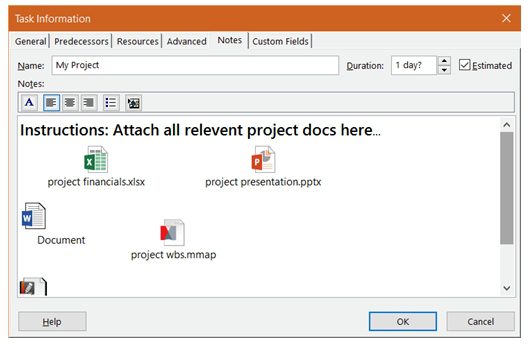
The Task Information/Notes dialog stores documents, turning your plan into a database!
It’s a best practice to do just that: attaching any preliminary documents and working plans, such as risk management plans or monitoring and evaluation plans, directly to your project file, thereby making any later analysis of your project that much easier.
When using Project as a project database, it’s helpful to start this recording from Day 1, and not just use the project plan as an implementation schedule. In short, begin your project plan in Project from the moment you begin to conceptualize the work all the way to the point your project either flies out the door or skids off the runway.
Using Project’s baseline function is a great way to keep track of your project’s flight and is at the heart of recording what takes place (or not) during the life of the project. Up to 11 baselines can be set for any given project, and these baselines show the differences between what you planned to happen, and what actually happened.

Baselines record the differences between planned and actuals
A “RAG” indicator is another great tool to use within Project. RAG stands for red-amber-green, but it’s best understood as warning indicators on your project’s flight deck. Just as there are colored lights in any jumbo jet’s cockpit, you need these types of indicators inside your project plan. Project comes with a built-in status indicator, but that’s not good enough. In this case you have to add a custom column and field, and use the formula function to build something more useful.
Fortunately, that’s much easier to do than it sounds, and this tutorial will get you started. Once built and added to your project plan, you will always know at a glance what tasks are late, in trouble, completed or coming up — great for experienced project pilots as well as for beginning co-pilots!

A simple RAG indicator becomes your cockpit’s early-warning system
Onto the Investigation
Now that your failed project’s “flight recorder” has been recovered, a proper investigation can begin with all the data on hand and in one place. The usual suspects are scrutinized one by one and, using the process of elimination, you can drill down to the root cause (or causes) of the failure.
As an excellent compilation on the International Project Power Skills Academy shares, project failures typically fall into 13 catastrophe categories:
[table id=32 /]
It’s important to note that during your investigation of a project crash, you may find more than one of the above catastrophes to be at the root of the project’s failure. Called the “cascade effect” in the airline biz, failures often start off small and build to a crescendo. Overall failure is often found to be the sum of many minor failures, and if one or more of the minor failures was caught in time, disaster might have been averted.
In Part 3 of this series, we’ll explore specific project disasters, outline what you can do to prevent future failures and also examine the idea of setting up a project safety board within your organization.
Read Part 1 of “Mayday! Project Crash Investigation,” here.
Read Part 3 of “Mayday! Project Crash Investigation,” here.
